OpenDBM CI CD Pipeline
Summary
OpenDBM CI CD Pipeline is very important as its job is to maintain the quality of the library for each new changes. The OpenDBM CI CD pipeline is divided into multiple sections that serve different purposes. Before OpenDBM dive into those sections, please see below the summary of the entirer pipeline flow.
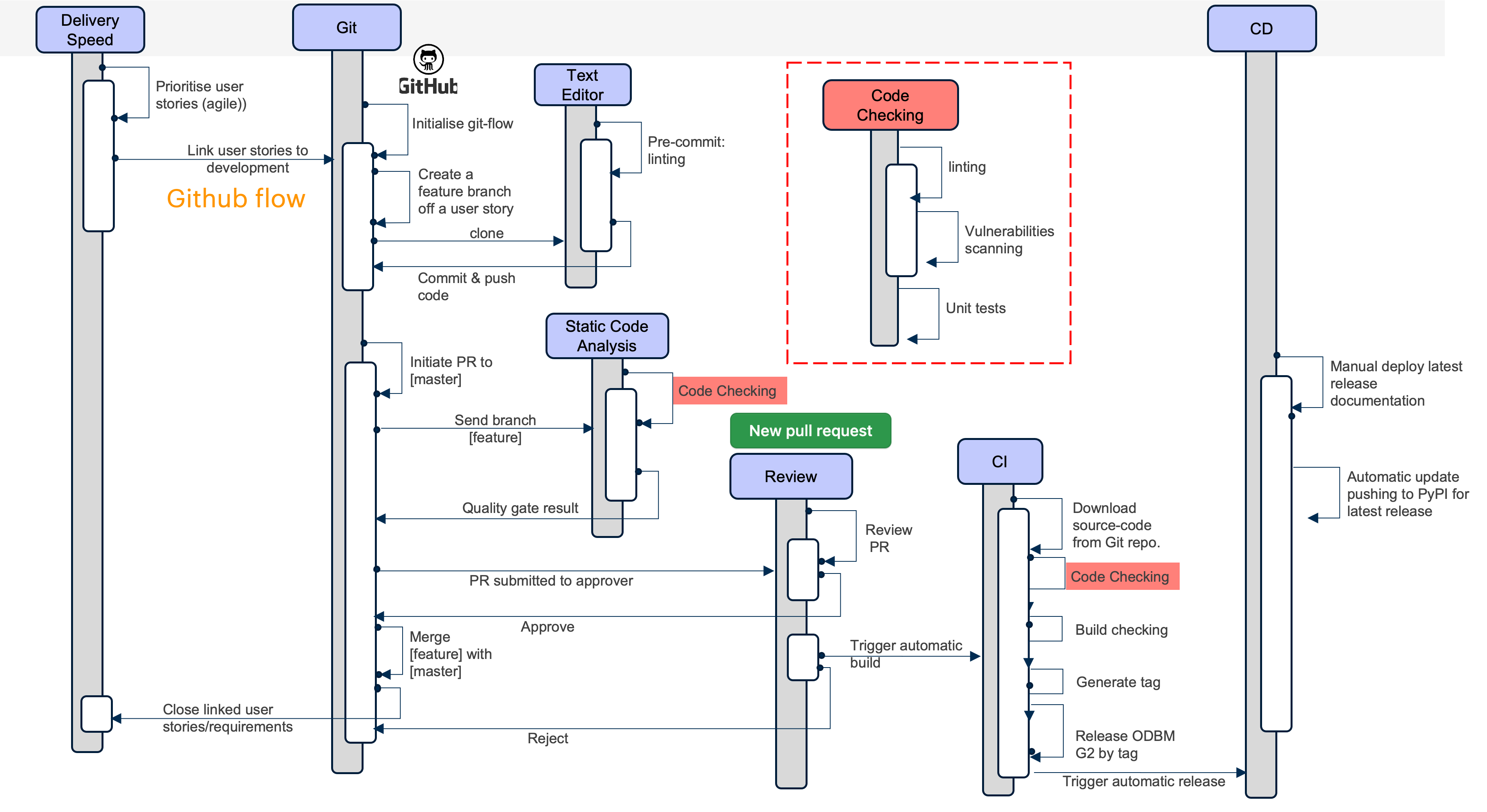
The git flow started when the community or OpenDBM team create stories to do. You can fork from master branch and named the fork based on the requirement (bug fix / enhancement). For instance if its enhancement, the fork name is feature/[github_name]/[feature_name]. The naming convention is not enforced for now but its a good practise to do so. Then after the feature developed and tested locally, the developer need to commit and push their changes into the their forked repository. But in doing so, there will be pre-commit checking which focused on linting will be executed. Upon success, the code will be pushed to your forked repo.
After it pushed, you need to create a pull request. After the PR is created, Github Actions will automatically trigger Code Checking chain processes, to make sure the code is clean and clear of vulnerabilities. It will also run the series of unit tests and run the test cases on different platform (MacOs, Windows, Linux). Only after the Code Checking success, the Release Manager can merge the PR.
After it merged, again the Github Actions will be executed Code Checking on the master branch. After the Code Checking is successful, the developers need to create the tag which marked as release version. When tag created successfully, it will again run the Code Check, and additionally it will run the automatic update of OpenDBM to PyPi.
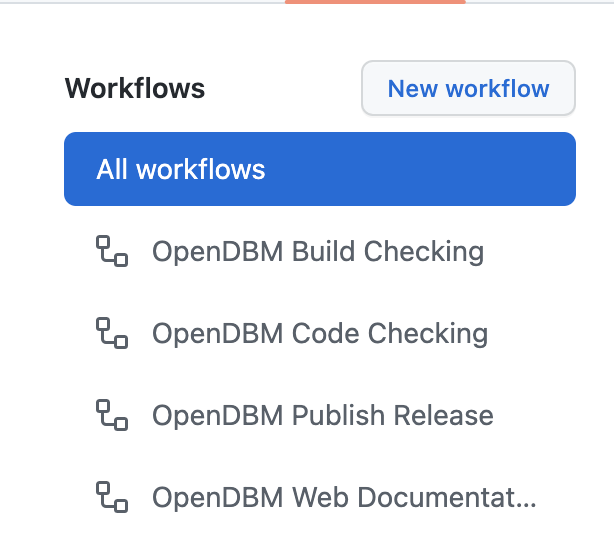
The OpenDBM is also using caching to speed up the pipeline deployment. So the installation and dependencies installation will be done in fast time. The only time needed is to download the cache into the github action container. You can check the cache key in job
- uses: actions/cache@v3in.github/workflows/open_dbm-code-checking.ymlfile.OpenDBM Code Checking
The configuration for this pipelines is located under
.github/workflows/open_dbm-code-checking.yml. Its the pipeline that will trigger in almost every git events. When you push your changes to your forked repository, it will run using your own github actions. It also only triggers when you change the files of the core library such as under dbm_lib directory. Any non-core files changes will not trigger this pipeline.
Linting
Linting is a way of detecting errors in code that can be solved with syntax or style changes. People often use linting to find simple errors, such as inconsistent spacing or formatting. This is generally more effective than merely running the code.
A good linter will often flag errors that the compiler would not catch. Often these are frivolous problems such as unused variables, but they serve to remind programmers about best practices and are sometimes harder for humans to catch when scanning through a large body of code. In Python, there are many options for linters including PyLint, black and pylama. In ODBM-G2, OpenDBM will use flake8 as our linter.
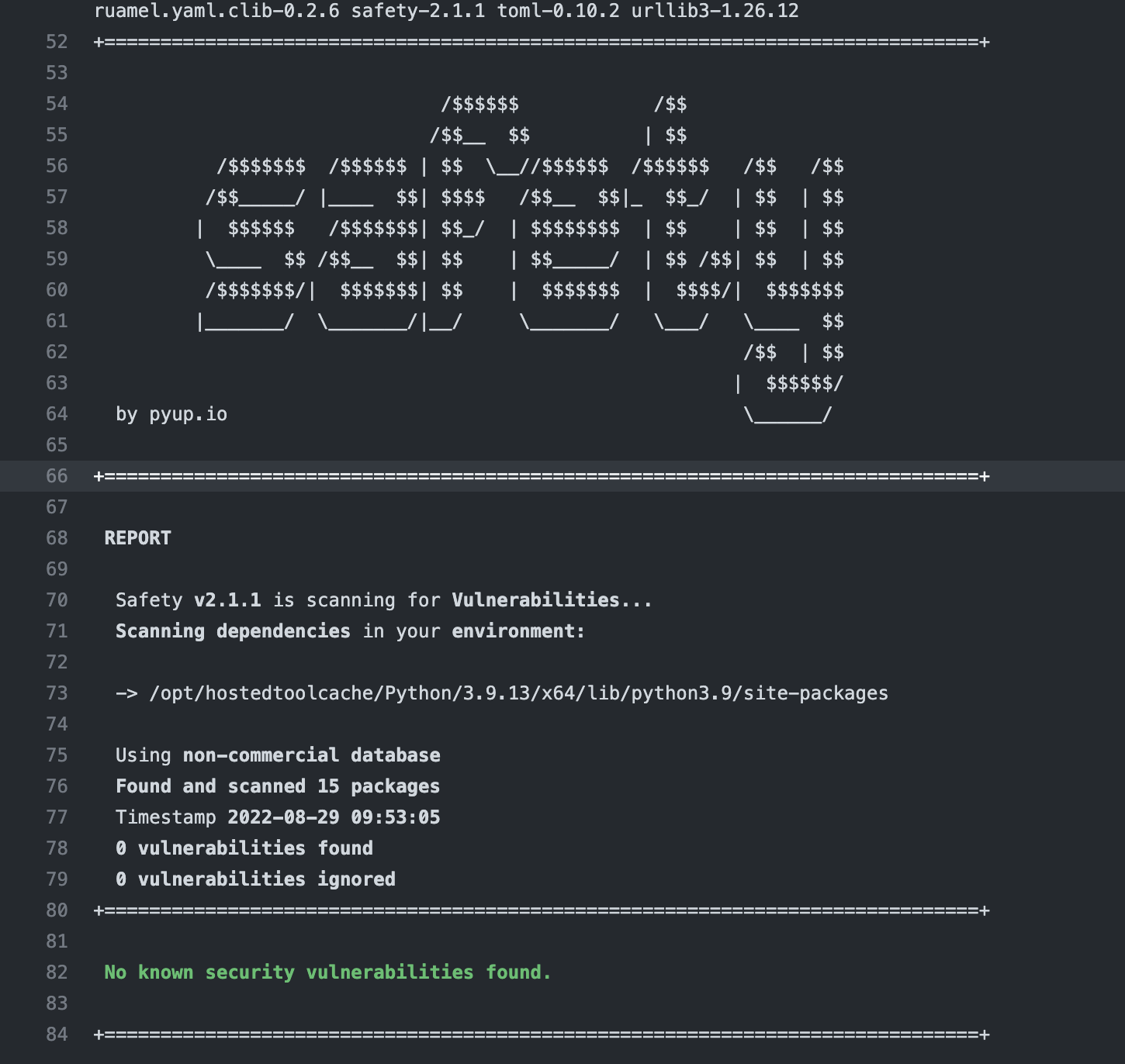
Vulnerabilities Scanning
With a 650% increase in next-gen cyberattacks against open source tools recorded in the last year, it is important to secure openDBM code by scanning the possible vulnerabilities from third party libraries.
ODBM-G2 will be using safety (https://pypi.org/project/safety) to scan the third party vulnerabilities.
Unit tests
Unit Test is a way to test every unit/component in codes. This unit can be a function, method, procedure, or module. Unit tests must be isolated from the original code to verify its correctness.
OpenDBM is using one of the most popular frameworks for unit testing, Pytest. Pytest framework is easier to read, more straightforward to write, and can be scalable to build complex testing.
In OpenDBM project, the unit test will be stored in Test folder. The Unit Test file structure will mimic OpenDBM File Structure to improve the readability / easier to check. For example, as below.
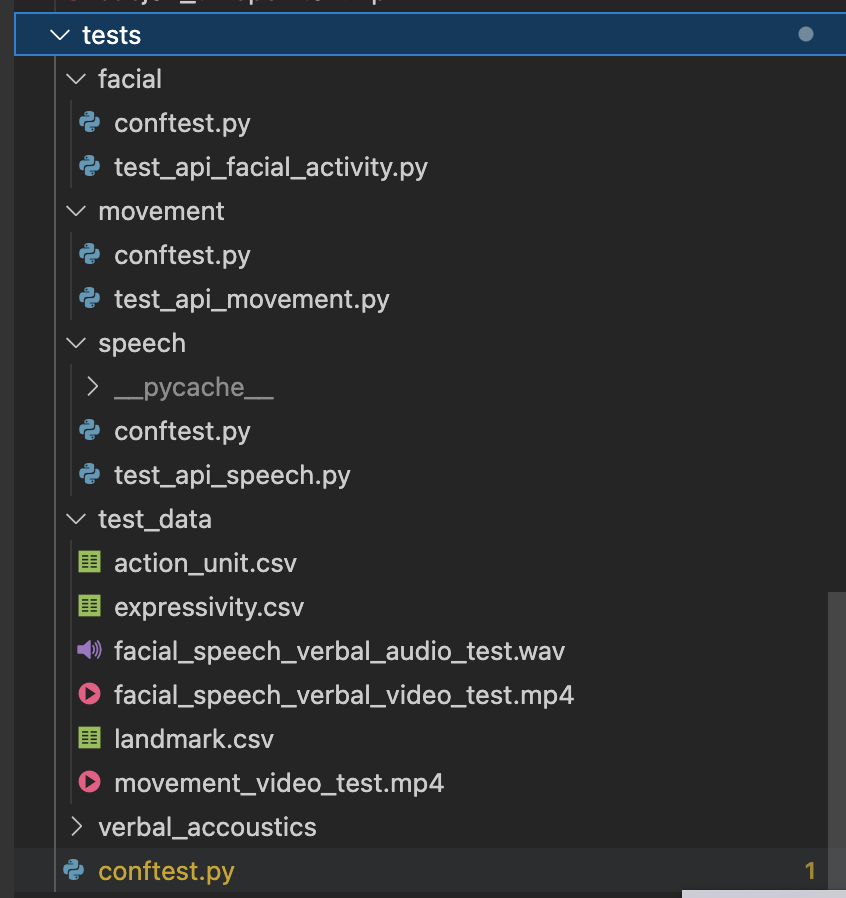
To have test case material, OpenDBM use video from various sources to generate all output from ODBM-G1. This video captures all the functionality that OpenDBM has, such as emotional expressivity, eye blink, head movement, speech, etc. The output that is stored in CSV files then are used as our material to do unit testing
There will be 2 types of expected output:
- Non-numeric. If the expected output is non-numeric, then in order to pass the test case, the new codes must generate precisely the same output as the previous codes.
- Numeric. If the expected output is numeric, then in order to pass the test case, the new codes should generate the same output as the previous codes with a margin of error. Formula for margin of error will be as follow: tol = max(rel_tol , abs_tol ) With tol = Tolerance value between actual output and expected output rel_tol = relative tolerance based on the magnitude of two numbers abs_tol= absolute tolerance (constant)
Formula above is a standard for Python PEP 485 for testing approximate equality
Currently the code coverage for OpenDBM is reaching 81%
OpenDBM Build Checking
This pipeline is to ensure the new changes that will merged to OpenDBM library still supporting one of the great things about OpenDBM, which is supporting all OS platforms. The pipeline not only ensure the installation process run without any problem in all platforms, but also to ensure the functionalities run without problem by executing the test cases in all platforms. If the one of the OS is/are failling due to new changes, it will be notified to the developer and OpenDBM team, and also generate failed badge and display it in the OpenDBM github pages
The pipeline will trigger if there is new Merge Request created.

OpenDBM Publish Release
This pipeline triggered only if the release manager create a release tag. There is also a condition in the pipeline that the release should not be draft / pre release tag. Only when official release created, it will run the pipeline that lives in .github/workflows/open_dbm-publish-release.yml, and publish the new version of OpenDBM library to PyPI
OpenDBM Web Documentation Deployment
This pipeline is to make deployment of OpenDBM Web documentation. The configuration file is in .github/workflows/open_dbm-docs-deploy.yml file. You can find the details about OpenDBM documentation here.
This pipeline only triggered manually. We can go to github actions, select OpenDBM Web Documentation Deployment, the choose the Run WorkFlow We need a proper Github Token that can build and push the github pages.
Github Environment Variables
GH_TOKEN : Its to update the badge based on conditions defined in the pipeline. It push the new badge status if there's any status difference after pipeline. Its also used to deploy the Web Documentation to Github pages TWINE_PASSWORD : Pipeline use this variable to push into the PyPI. By default the pipeline use token as the username, indicates that to push to PyPI we will use token instead of credentials