Docker Output
OpenDBM Output
In the previous chapter, we went over how to process data using OpenDBM and learned that when we do so, we save a folder called output in the location we specify. This chapter is all about what’s in that folder and all the wonderful things we can do with it.
The first thing you’ll see is that the output folder is divided into raw_variables and derived_variables. As Chapter 5 explains, for each biomarker, both raw variables and derived variables are calculated. Raw variables are often frame-wise values containing measurements according to the temporal resolution of the inputted file (e.g. happiness expressivity in each frame of video in an inputted video file or audio intensity for each audio frame in an audio file). Derived variables are abstractions of their respective raw variables (e.g. average happiness expressivity across a video or standard deviation of audio intensity over the course of the audio file). Chapter 5 goes into more detail and lists all raw and derived biomarker variables. The purpose of this chapter is to first just explain the structure of the data output from OpenDBM.
Derived Variables
For derived variables, a single CSV file is outputted. This CSV file, named derived_output.csv, contains a row for each video/audio file that was inputted. If only a single file was processed, the CSV file will have only one row. If several were inputted, then several rows will be outputted.
And, in case you forgot what files and/or excel sheets look like, here are some illustrations:
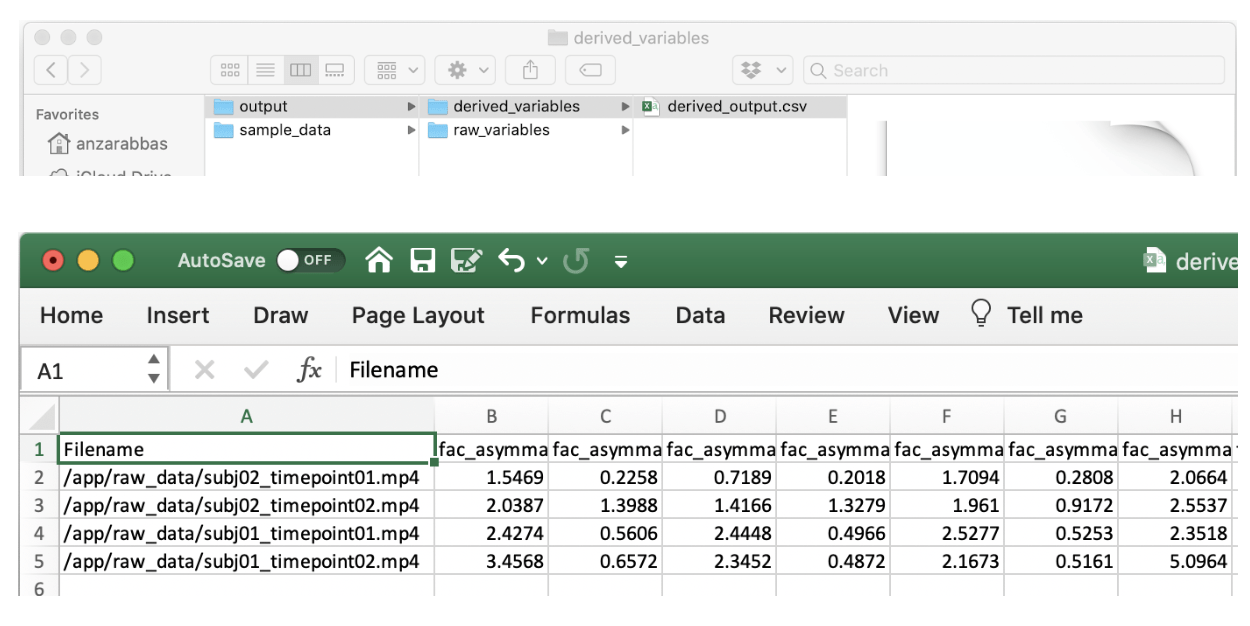
Essentially, the derived variables CSV file is the best place to go for most simple analyses. In this instructional video, we conduct a sample data analysis in a made-up experiment and use the derived variable output to test effects of a ‘treatment’ on emotional expressivity in the face.
Raw Variables
The raw variable data structure is slightly more complicated. The hierarchy is described below:
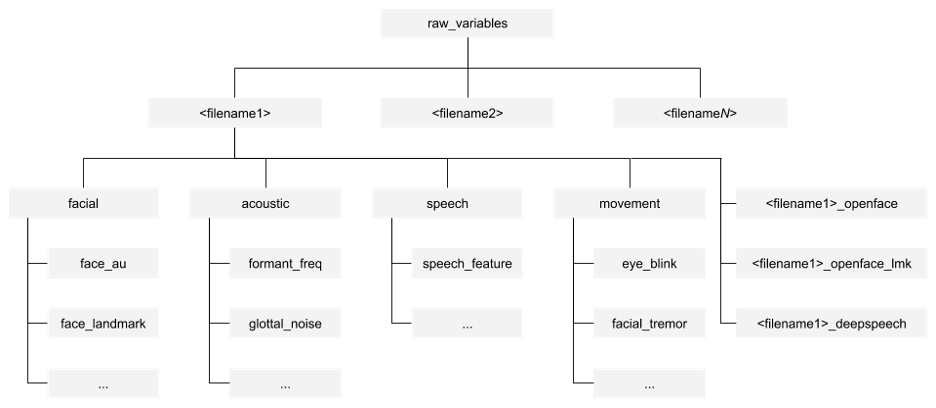
Under the raw_variables folder, there will be a folder for each filename. Under each filename’s folder, there will be a folder for each DBM group as described in Section 3.1.3 and Chapter 5: facial, acoustic, speech, and movement. In each of the DBM group folders, there will be sub- folders for biomarkers e.g. the acoustic intensity folder has data for audio intensity (Section 5.2.3). WIthin the biomarker folder will be a CSV file that contains frame-by-frame values for variables in it. In the case of audio intensity, the audio intensity raw variable CSV file has the aco_int values in decibels for each frame of audio in the video file, whereas the aco_int_mean derived variable would simply have the mean intensity of all frames in that file.
OpenFace output
As has been mentioned before, OpenDBM relies on OpenFace for a lot of its measurements. In case the user is interested in going upstream to that level of data, the <filename>_openface folder just contains the OpenFace output, including action units, eye gaze data, and head movement calculations. Some other facial and movement measurements are acquired using facial landmark data, which is also an output from OpenFace, though relies on a different model. That OpenFace data is saved in <filename>_openface_lmk. Both of the raw OpenFace output folders are there in case a user is interested in building their own raw / derived variables. If the user is simply interested in using OpenDBM’s existing measures, they can ignore these folders.
Speech transcription
Assuming the user used the --tr=on option when executing the processing command, OpenDBM will save the text for any speech that was transcribed in a folder called deepspeech. All transcription is done using an open source software package called DeepSpeech This folder simply contains the output that DeepSpeech provides. Similar to the OpenFace output, the speech transcription is saved in case the user wants to dig deeper and perhaps derive their own measures. We do ask that you read Section 3.1.4 before you save speech transcriptions.